Large language models in the understanding of the systemic impacts of extreme events
Mariana M. de Brito
Core Questions
- How does unstructured text data reveal actionable information about systemic socio-economic impacts of climate hazards?
- What do they tell about responses and adaptation measures?
Abstract
Much of the scientific findings, public discourse, and political framing are documented as text. Facing digitalization, these are now aggregated in newspaper repositories, social media platforms, and archives of peer-reviewed articles. This large volume of digitalized text data, combined with advancements in the field of natural language processing (NLP), has opened new scalable ways of extracting actionable information from texts. A recent development is the use of large language models (LLMs), which are capable of understanding and generating human-like texts. By leveraging these tools and datasets, we can reveal hidden patterns in texts and derive insights for managing the risks posed by multi-hazards that were previously unattainable.
In this lecture, I will present how unstructured text data (e.g. newspapers, reports, meeting minutes) can be used to obtain actionable information on the systemic socio-economic impacts of climate hazards as well as the response and adaptation measures adopted.
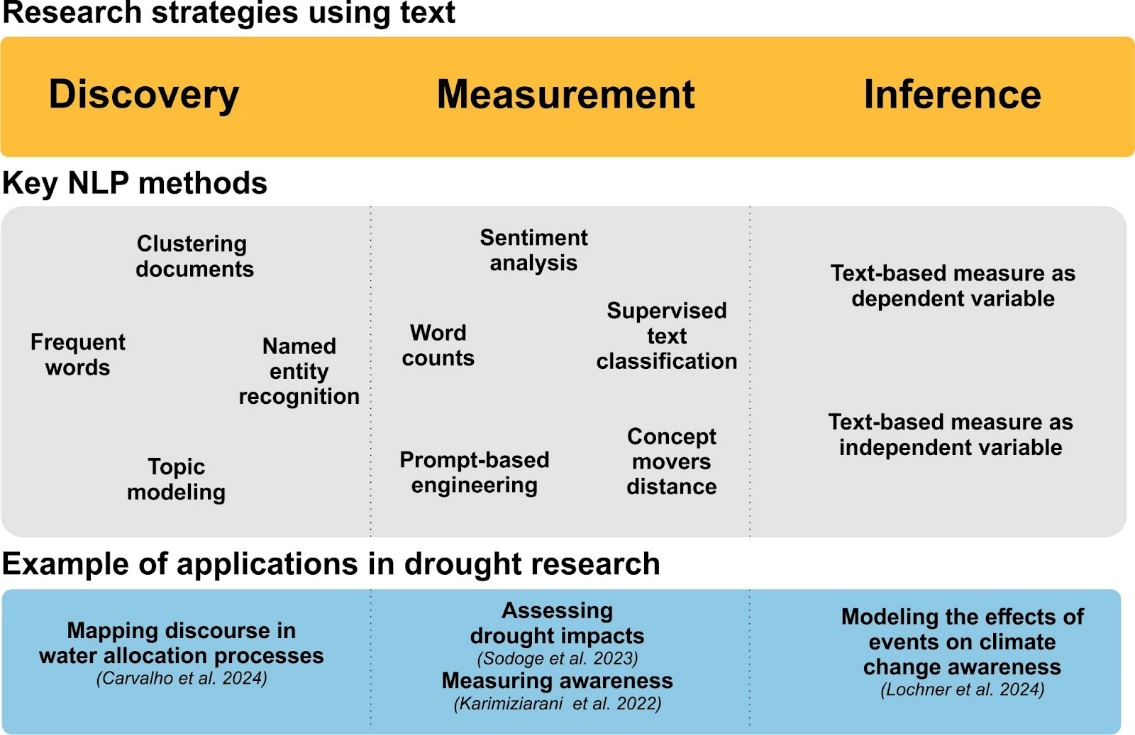 Three ways text can be used in multi-hazard and climate change-related research: discovery, measurement, and inference (based on Grimmer et al., 2022).
Three ways text can be used in multi-hazard and climate change-related research: discovery, measurement, and inference (based on Grimmer et al., 2022).
Literature
- Carvalho, T. M. N., de Souza Filho, F. de A., & de Brito, M. M. (2024). Unveiling water allocation dynamics: a text analysis of 25 years of stakeholder meetings. Environmental Research Letters, 19(4), 044066.
- Grimmer, J., Roberts, M. E., & Stewart, B. M. (2022). Text as Data: A New Framework for Machine Learning and the Social Sciences. Princeton University Press.
- Lochner, J. H., Stechemesser, A., & Wenz, L. (2024). Climate summits and protests have a strong impact on climate change media coverage in Germany. Communications Earth & Environment, 5(1).
- Sodoge, J., Kuhlicke, C., & de Brito, M. M. (2023). Automatized spatio-temporal detection of drought impacts from newspaper articles using natural language processing and machine learning. Weather and Climate Extremes, 41(100574), 100574.
Talk on 23 January 2025 — Ringvorlesung in Winter Term 2024/25